1. Introduction
When training a machine learning model, especially Logistic Regression, we want the model to generalize well to unseen data. However, as we saw with overfitting, a model can:
- Fit the training data perfectly
- Learn noise instead of the true pattern
- Perform poorly on new data
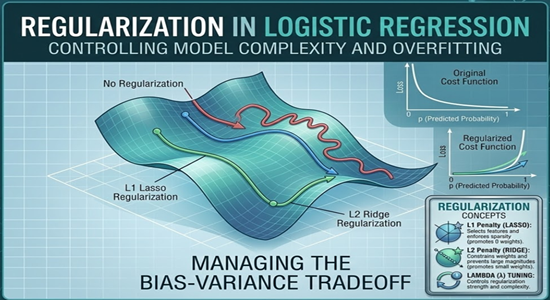
Regularization is a technique that prevents overfitting by penalizing large weights in the model.
2. Types of Regularization
| Type | Penalty Term | Effect |
|---|---|---|
| L1 (Lasso) | ||
| L2 (Ridge) | Shrinks all weights, smooth the model, and avoids extreme values |
2.1. L1 (Lasso) Regularization
Use L1 regularization when you want automatic feature selection.
Typical scenarios:
1. High-dimensional datasets
When the dataset has many features but only some are important. Example: text classification, gene expression data.
2. Sparse solutions are preferred
L1 pushes many weights exactly to zero, effectively removing irrelevant features.
3. Model interpretability is important
Because many coefficients become zero, the remaining features clearly show which variables influence predictions.
Example Applications:
- Spam detection (thousands of word features)
- Genomics / bioinformatics
- NLP feature selection
2.2 L2 Regularization (Ridge)
Use L2 regularization when all features contribute somewhat and you mainly want to reduce overfitting without eliminating features.
Typical scenarios:
1. Multicollinearity (highly correlated features)
L2 distributes weights among correlated variables rather than eliminating them.
2. When most features are useful
Instead of removing features, L2 shrinks their magnitudes smoothly.
3. More stable models
It creates smooth decision boundaries and reduces variance.
Example Applications:
- Regression with many correlated predictors
- Neural networks (commonly called weight decay)
- Financial prediction models